
隐藏的 Electron 窗口和内核级文件夹代理,让 AI 能够在不影响用户的情况下迭代代码。
这是一个失败的方案:把几个相关文件粘贴到 Google Doc 中,把链接发给你最喜欢的 p60 软件工程师(他对你的代码库一无所知),然后让他们在文档中完整且正确地实现你的下一个 PR。
让 AI 做同样的事情,也会可预见地失败。
相反,如果给他们远程访问你的开发环境的权限,让他们能够看到代码检查、跳转到定义并运行代码,你可能会期望他们能够提供一些帮助。
我们相信,让 AI 能够编写更多代码的关键之一是让它能够在你的开发环境中进行迭代。但是,简单地让 AI 在你的文件夹中自由运行会导致混乱:想象一下,当你正在编写一个需要深入思考的函数时,AI 突然覆盖了它,或者当你试图运行程序时,AI 插入了无法编译的代码。为了真正有帮助,AI 的迭代需要在后台进行,而不影响你的编码体验。
为了实现这一点,我们在 Cursor 中实现了我们称之为 shadow workspace 的功能。在这篇博文中,我将首先概述我们的设计标准,然后描述当前在 Cursor 中实现的方案(一个隐藏的 Electron 窗口)以及我们未来的发展方向(一个内核级文件夹代理)。

设计标准
我们希望 shadow workspace 能够实现以下目标:
- LSP 可用性:AI 应该能够看到它们更改的代码检查结果,能够跳转到定义,以及更广泛地与语言服务器协议(LSP)的所有部分进行交互。
- 可运行性:AI 应该能够运行它们的代码并查看输出。
我们最初专注于 LSP 可用性。
这些目标应该在满足以下要求的前提下实现:
- 独立性:用户的编码体验不能受到影响。
- 隐私性:用户的代码应该是安全的(例如,通过保持所有内容都在本地)。
- 并发性:多个 AI 应该能够同时工作。
- 通用性:它应该适用于所有语言和所有工作区设置。
- 可维护性:它应该使用尽可能少且可隔离的代码编写。
- 速度:任何地方都不应该有长达一分钟的延迟,并且应该有足够的吞吐量来处理数百个 AI 分支。
这些要求中的许多都反映了为超过十万用户构建代码编辑器的现实。我们真的不想对任何人的编码体验产生负面影响。
实现 LSP 可用性
让 AI 获取其编辑的代码检查结果是在保持底层语言模型不变的情况下提高代码生成性能的最有效方法之一。代码检查不仅可以帮助将 90% 可用的代码提升到 100% 可用,而且在上下文受限的情况下也非常有帮助,当 AI 可能需要在第一次尝试时对调用哪个方法或服务做出明智的猜测时。代码检查可以帮助识别 AI 需要请求更多信息的地方。

LSP 可用性也比可运行性更简单,因为几乎所有的语言服务器都可以处理未写入文件系统的文件(正如我们稍后会看到的,涉及文件系统会使事情变得相当困难)。所以让我们从这里开始!本着我们的第五个要求——可维护性的精神,我们首先尝试了最简单的解决方案。
不起作用的简单解决方案
Cursor 是 VS Code 的一个分支,这意味着我们已经可以很容易地访问语言服务器。在 VS Code 中,每个打开的文件都由一个 TextModel 对象表示,该对象在内存中存储文件的当前状态。语言服务器从这些文本模型对象而不是从磁盘读取,这就是它们可以在你输入时(而不是仅在保存时)提供补全和代码检查的原因。
假设 AI 对文件 lib.ts 进行了编辑。我们显然不能修改与 lib.ts 对应的现有 TextModel 对象,因为用户可能同时在编辑它。然而,一个听起来合理的想法是创建 TextModel 对象的副本,将副本与磁盘上的任何实际文件分离,并让 AI 编辑并从该对象获取代码检查。这可以通过以下 6 行代码实现。
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// 创建复制的内存中 TextModel 并应用 AI 编辑
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// 等待 2 秒以允许语言服务器处理新的 TextModel 对象
await new Promise((resolve) => setTimeout(resolve, 2000));
// 从标记服务读取代码检查,它会根据语言内部路由到�正确的扩展
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}
这个解决方案在可维护性方面显然是出色的。它在通用性方面也很好,因为大多数人已经为他们的项目安装和配置了正确的特定语言扩展。并发性和隐私性也很容易满足。
问题在于独立性。虽然创建 TextModel 的副本意味着我们不会直接修改用户正在编辑的文件,但我们仍然会告诉语言服务器(用户正在使用的同一个语言服务器)我们的复制文件的存在。这会导致问题:跳转到引用的结果会包含我们的复制文件,像 Go 这样具有多文件默认命名空间作用域的语言会对复制文件和用户可能正在编辑的原始文件中的所有函数重复声明发出警告,而像 Rust 这样只有在其他地方显式导入文件时才包含文件的语言根本不会给出任何错误。可能还有很多类似的问题。
你可能认为这些问题听起来很小,但独立性对我们来说是绝对关键的。如果我们稍微降低了编辑代码的正常体验,那么我们的 AI 功能有多好都无关紧要——人们,包括我自己,都不会使用 Cursor。
我们还考虑了一些其他最终失败的想法:在 VS Code 基础设施之外生成我们自己的 tsc 或 gopls 或 rust-analyzer 实例,复制运行所�有 VS Code 扩展的扩展主机进程,这样我们就可以运行每个语言服务器扩展的两个副本,以及分叉所有流行的语言服务器以支持文件的多个不同版本,然后将这些扩展捆绑到 Cursor 中。
当前的 Shadow Workspace 实现
我们最终将 shadow workspace 实现为一个隐藏窗口:当 AI 想要查看它编写的代码的代码检查时,我们会为当前工作区生成一个隐藏窗口,然后在该窗口中进行编辑,并报告代码检查结果。我们在请求之间重用隐藏窗口。这为我们提供了(几乎*)完整的 LSP 可用性,同时(几乎*)完全满足所有要求。星号稍后会解释。
简化的架构图如图 4 所示。
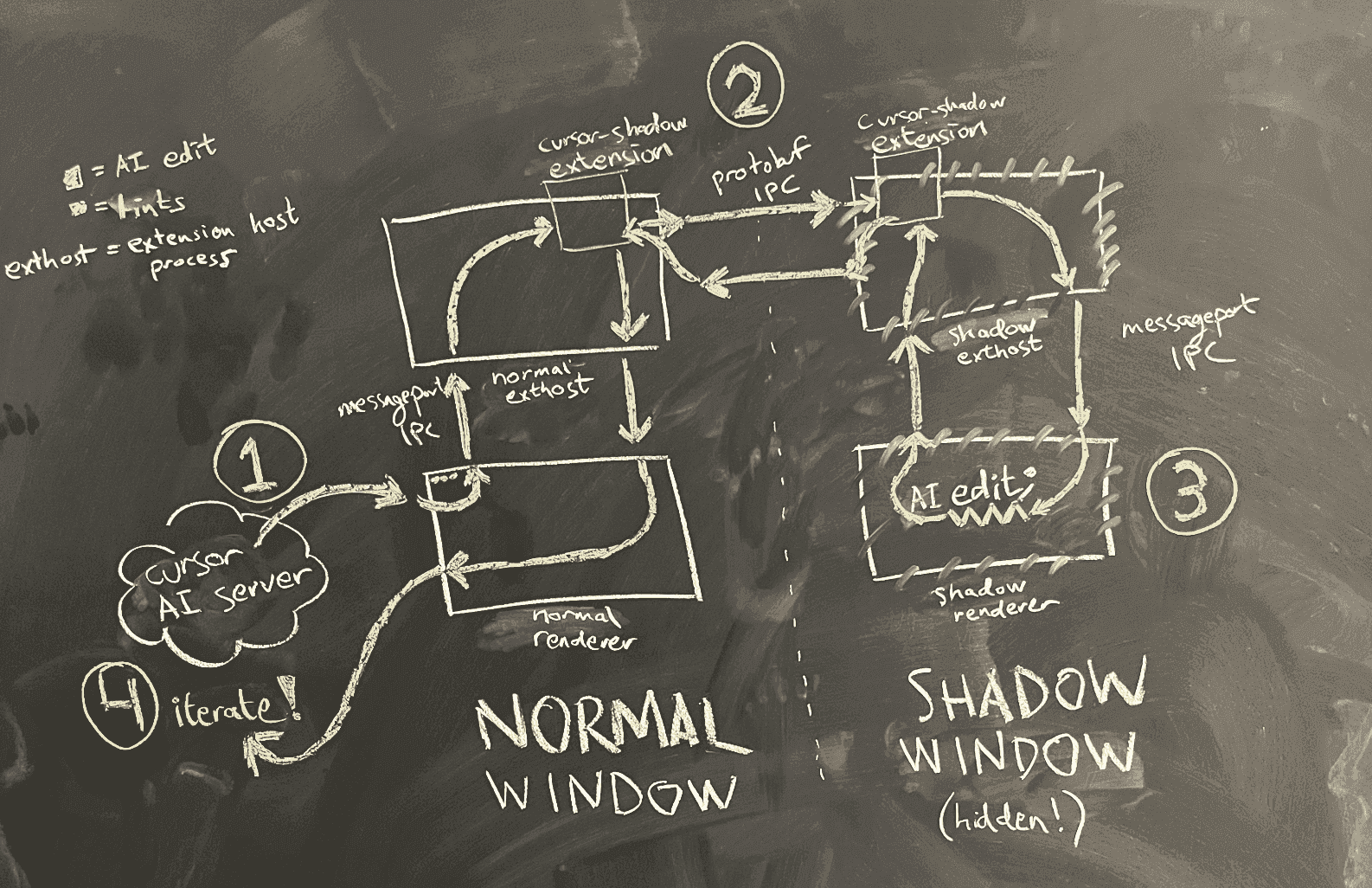
AI 在普通窗口的渲染进程中运行。当它想要查看它编写的代码的代码检查时,渲染进程要求主进程在同一文件夹中生成一个隐藏的影子窗口。由于 Electron 沙箱的原因,两个渲染进程不能直接相互通信。我们考虑过的一个选项是重用 VS Code 实现的用于让渲染进程与扩展主机进程通信的消息端口创建逻辑,并使用它来创建我们自己的普通窗口和影子窗口之间的消息端口 IPC。
谨慎对待可维护性负担,我们选择了一个技巧:我们重用了 VS Code 的扩展主机 IPC 基础设施。每个窗口都有自己的扩展主机进程,但是这些进程可以相互通信。这意味着我们可以将编辑从普通窗口的渲染进程发送到其扩展主机,然后发送到影子窗口的扩展主机,最后发送到影子窗口的渲染进程。
这种方法的优点是我们不需要编写任何新的 IPC 代码。缺点是我们依赖于 VS Code 的内部 IPC 基础设施,这可能会在未来发生变化。然而,考虑到我们已经依赖于 VS Code 的许多其他内部 API,这似乎是一个合理的权衡。
实现可运行性
现在我们已经解决了 LSP 可用性问题,让我们来看看可运行性。这里的挑战是,当 AI 想要运行代码时,它需要将其更改写入磁盘。这引入了一个新的要求:磁盘级独立性。我们不能让 AI 的更改影响用户的文件系统。
一个简单的解决方案是为每个 AI 创建一个工作区的副本。这确实可以工作,但有几个问题:
- 创建工作区副本可能很慢,特别是对于大型项目。
- 如果有多个 AI 同时工作,我们需要为每个 AI 创建一个副本,这会占用大量磁盘空间。
- 如果工作区包含大型二进制文件或构建产物,复制它们会特别慢且浪费空间。
相反,我们希望有一个更智能的解决方案:一个代理文件夹,它看起来像工作区的副本,但实际上只存储 AI 的更改。当 AI 尝试读取一个文件时,如果该文件在代理文件夹中不存在,则从原始工作区读取。当 AI 尝试写入一个文件时,更改只存储在内存中而不是写入磁盘。简而言之,我们想要一个具有可配置覆盖的代理文件夹,我们很乐意将覆盖表完全保存在内存中。然后,我们可以在这个代理文件夹中生成我们的影子窗口,并实现完美的磁盘级独立性。
关键是,我们需要内核级支持来实现文件夹代理,这样任何运行的代码都可以继续调用 read 和 write 系统调用而无需任何更改。一种方法是创建一个内核扩展,将自己注册为内核虚拟文件系统中影子文件夹的后端,并实现上述简单行为。
在 Linux 上,我们可以使用 FUSE("用户空间文件系统")在用户级别实现这一点。FUSE 是一个默认存在于大多数 Linux 发行版中的内核模块,它将文件系统调用代理到用户级进程。这使得实现文件夹代理变得更加简单。下面是一个文件夹代理的玩具实现,用 C++ 编写。
首先,我们导入用户级 FUSE 库,它负责与 FUSE 内核模块通信。我们还定义了目标文件夹(用户的文件夹)和内存中的覆盖映射。
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// 其他引入...
using namespace std;
// 我们不想修改的代理文件夹
string target_folder = "/path/to/target/folder";
// 要应用的内存中覆盖
unordered_map<string, vector<char>> overrides;
然后,我们定义我们的自定义 read 函数来检查覆盖是否包含该路径,如果不包含,就从目标文件夹读取。
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 检查路径是否在覆盖中
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// 如果是,返回覆盖的内容
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// 否则,从代理文件夹打开并读取文件
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}
我们的自定义 write 函数只是写入覆盖映射。
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 始终写入覆盖
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}
最后,我们向 FUSE 注册我们的自定义函数。
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}
真实的实现需要实现整个 FUSE API,包括 readdir 和 getattr 和 lock,但这些函数会与上面的函数非常相似。对于每个新的代码检查请求,我们可以简单地将覆盖映射重置为仅包含该特定 AI 的编辑,这是即时的。如果我们想要防止内存爆炸,我们也可以将覆盖映射保存在磁盘上(需要一些额外的记账工作)。
在完全控制环境的情况下,我们可能希望将其实现为原生内核模块,而不是使用 FUSE,以避免 FUSE 带来的额外用户-内核上下文切换开销。
...但是:围墙花园
对于 Linux,FUSE 文件夹代理工作得很好,但我们的大多数用户使用 macOS 或 Windows,这两个系统都没有内置的 FUSE 实现。不幸的是,发布内核扩展也是不可能的:在使用 Apple Silicon 的 Mac 上,用户安装内核扩展的唯一方法是在按住特殊键进入恢复模式时重启计算机,然后降级到"降低安全性"。这是无法发布的!
由于 FUSE 部分需要在内核中运行,像 macFUSE 这样的第三方 FUSE 实现也面临着同样的无法让用户安装的问题。
已经有人尝试在这个限制下寻找创造性的解决方案。一种方法是采用 macOS 原生支持的基于网络的文件系统(例如,NFS 或 SMB),并在其下添加 FUSE API。在 xetdata/nfsserve 上有一个基于 NFS 构建的具有类 FUSE API 的开源概念验证本地服务器,而闭源项目 macOS-FUSE-t 支持基于 NFS 和 SMB 的后端。
问题解决了吗?并没有...文件系统比仅仅读取、写入和列出文件要复杂得多!这里,Cargo 抱怨是因为 xetdata/nfsserve 实现所��基于的早期版本 NFS 不支持文件锁定。

MacOS-FUSE-t 是基于支持文件锁定的 NFSv4 构建的,但 GitHub 仓库只包含三个非源代码文件(Attributions.txt、License.txt、README.md),并且是由一个可疑的单一用途 GitHub 账户 macos-fuse-t 创建的,没有更多信息。显然,我们不能向用户发布随机的二进制文件...未解决的问题也表明基于 NFS/SMB 的方法存在一些更基本的问题,主要与 Apple 内核错误有关。
我们还剩下什么?要么是一个新的创造性方法,要么是...政治!Apple 十年来逐步淘汰内核扩展的过程导致他们开放了越来越多的用户级 API(如 DriverKit),他们对文件系统的内置支持最近也已切换到用户空间。他们的开源 MS-DOS 代码在这里引用了一个名为 FSKit 的私有框架,这听起来很有希望!感觉通过一些政治手段,我们可能会让他们最终向外部开发者发布 FSKit(或者他们可能已经在计划这样做了?),在这种情况下,我们可能也会有一个解决 macOS 可运行性问题的方案。
开放问题
正如我们所见,让 AI 在后台迭代代码这个看似简单的问题实际上相当复杂。shadow workspace 是一个为期一周的单人项目,旨在创建一个实现来解决我们当前向 AI 显示代码检查的需求。在未来,我们计划扩展它以解决可运行性问题。以下是一些开放性问题:
-
是否有其他方法可以在不创建内核扩展或使用 FUSE API 的情况下实现我们��想要的简单代理文件夹?FUSE 试图解决一个更大的问题(任何类型的文件系统),因此在 macOS 和 Windows 上可能存在一些晦涩的 API,这些 API 适用于我们的文件夹代理,但不适用于通用的 FUSE 实现。
-
Windows 上的代理文件夹故事具体是什么样的?像 WinFsp 这样的东西是否可以直接使用,还是存在安装、性能或安全问题?我花了大部分时间研究如何在 macOS 上实现文件夹代理。
-
也许有办法在 macOS 上使用 DriverKit 并模拟一个假的 USB 设备来充当代理文件夹?我对此表示怀疑,但我还没有仔细研究 API,无法确定地说这是不可能的。
-
我们如何实现网络级独立性?一个特殊的情况是当 AI 想要调试一个集成测试,其中代码分布在三个微服务之间。可能我们需要做一些更像 VM 的事情,尽管这需要更多的工作来确保整个环境设置和所有已安装软件的等效性。
-
是否有一种方法可以从用户的本地工作区创建一个相同的远程工作区,同时尽可能减少用户需要的设置?在云中,我们可以直接使用 FUSE(或者如果需要性能,甚至可以使用内核模块),而不需要做任何政治工作,我们还可以保证用户不会有额外的内存使用,并且完全独立。对于那些不太关心隐私的用户来说,这可能是一个很好的替代方案。一个初步想法是通过观察系统来自动推断 docker 容器(可能使用编写脚本来检测机器上运行的内容,并使用语言模型来编写 Dockerfile 的组合)。
如果你对这些问题有好的想法,请发邮件给我:arvid@anysphere.inc。另外,如果你想从事这样的工作,我们正在招聘。